A Minimal AI Development Lifecycle That Actually Works
Stop getting inconsistent AI-generated code. Learn a minimal Boostrap → [Execute → Ship] loop using Claude Code that keeps you in control without drowning in markdown files.


I originally planned to write about setting up instructions.md and prompts.md with GitHub Copilot. By the time I finished experimenting, that post was already outdated.
That's the AI era in a nutshell: blink, and the best practice has moved on.
The Landscape Has Shifted (And Keeps Shifting)
A year ago, the skill was prompt engineering — knowing how to ask the right question. Now it's about context engineering — setting up AGENTS.md, CLAUDE.md, skills.md, and MCP servers so your AI has everything it needs to act autonomously for hours at a time.
Addy Osmani described this shift well in his Factory Model post: developers are no longer writing code directly. They're building the factory that builds the software — managing autonomous agents, each with specific tasks, toolbelts, and feedback loops. He notes that "new website creation is up 40% year over year" and "new iOS apps are up nearly 50%", driven by this shift.
I subscribe to Claude just to experience what all the buzz was about, while still using GitHub Copilot at work. What I found convinced me to invest two weeks — on and off — figuring out a workflow that doesn't require me to babysit the AI or drown in boilerplate spec files.
Note: Claude Code isn't locked to one model. If you use hosted model such as Kimi, Qwen, or ollama, you can configure Claude Code to work with those providers too.
Why "Just Use Chat" Doesn't Scale
Before I share the workflow, here's the problem it solves.
If you generate a feature by chatting with an AI directly — no persistent context, no spec — you will get inconsistent code. The AI doesn't remember your architectural decisions, your naming conventions, or the choices you made three features ago. Every chat session starts fresh, and the codebase drifts.
The fix isn't more prompting skill. It's structured context that persists across sessions.
The Minimal AI Development Lifecycle
After reviewing the spec-driven development frameworks in the market, I found most of them bloated — too many files, too many tools to install, too much process overhead. I wanted the simplest loop that is still feature-focused and works for real applications: frontend, backend, and worker services.
Here's what I settled on:
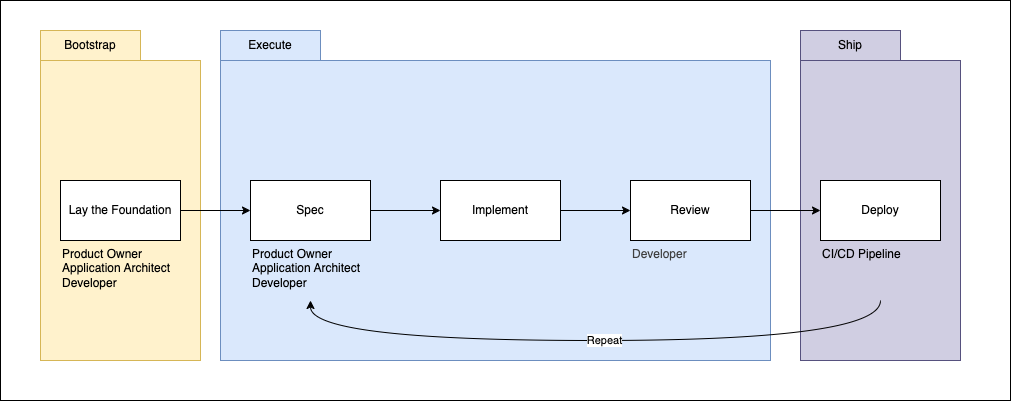
Three phases. One README. One PRD per feature, implement one at the time, review, deploy and repeat.
Phase 1: Bootstrap — Get Your README Right
Everything starts with README.md. Don't overthink the structure — just put everything in and refactor when needed.
Start in Claude Code's Plan Mode, which helps you to brainstorm your application high level requirements. Iterate until the plan feels right, then save it to your README.
Here's the minimal structure I use:
# Application Name
Overall what this application does.
## Problem
What problem is this application solving?
## Key Features
Keep it blank on init, AI will help adding it when PRD is implemented.
## Architecture
Key architectural decisions the AI should understand and respect. For example:
- **Modular monolith** — codebase split into self-contained modules (e.g. Billing, Inventory, Auth), deployed as a single unit
- **Multi-tenant shared database** with `tenant_id` on every table
- Row-level security (RLS) at database layer + ORM middleware at application layer
## Tech Stack
Components and libraries used across the project. For example:
- Frontend: Next.js (React, TypeScript)
- Backend: ASP.NET Core REST API (Entity Framework)
- Database: PostgreSQL
- Message Broker: RabbitMQ (MassTransit)
- Worker: ASP.NET Core Worker Service
- Testing: xUnit, Playwright
That's it. No lengthy AGENTS.md boilerplate yet. No elaborate folder conventions. Just enough signal for the AI to orient itself.
Why this matters: The README becomes the source of truth for every PRD you create later. If it's vague, the PRDs will be vague, and as Addy Osmani puts it: "Vague prompts mean wrong results." Specification quality determines output quality at scale.
Phase 2: Execute — PRD + Autonomous Loop + Review, Merge
Once the README is solid, you move feature by feature. Each feature gets a PRD.
Writing the PRD
I adapted the PRD structure from the ralph-tui skill, trimmed down to what I actually need. The PRD lives at .spec/<feature-name>.md:
## Branch Name
feature/your-feature-name
## Overview
One paragraph summary.
## Goal
What success looks like.
## User Stories
- Story ID: US-001
As a [user type], I want [action] so that [outcome]
- Details
- Acceptance Criteria
- passes: false
## Cross-Cutting Scenarios
Edge cases, error states, permissions.
## Data Model
Key entities and relationships.
## Out of Scope
Explicitly list what this PRD does NOT cover.
## Architecture Notes
Any decisions the AI should respect.
The passes: false field on each story is important — ralph uses it to track which stories are done. When a story is completed, it flips to passes: true. When all stories are true, the loop stops.
Before handing off to ralph, make sure your PRD goes beyond just user stories. Three areas that teams consistently underspecify are non-functional requirements, API contract design, and data modeling — and all three will bite you later if left vague.
For non-functional requirements, be explicit about things like latency targets, throughput expectations, error rate thresholds, and security constraints. "It should be fast" is not a spec. "p99 response time under 200ms at 500 RPS" is. The same goes for availability, data retention, and observability hooks — if you don't write it down, ralph won't guess it.
For API design, the choice of protocol matters and should be a deliberate decision in the spec. If you're building a RESTful API, define your resource hierarchy, HTTP verbs, status code conventions, and pagination strategy upfront. If you're going gRPC, specify your .proto service definitions, streaming patterns (unary vs. server-streaming vs. bidirectional), and how you'll handle versioning. Mixing these concerns in mid-implementation is expensive — the PRD is the right place to lock them in.
For data modeling, sketch out your core entities, their relationships, and the key fields before a single migration is written. Decide early whether you're normalizing for integrity or denormalizing for read performance. Call out your indexing strategy for high-traffic queries, any soft-delete patterns, and how you'll handle schema evolution over time — whether that's versioned migrations, backward-compatible column additions, or something else. If you're mixing storage engines (say, Postgres for relational data and Redis for caching), the PRD should define the boundary between them. The database schema is one of the hardest things to change mid-flight, so getting alignment here before ralph starts generating code saves you from painful refactors down the line.
Review the PRD with your team before handing it off. The AI doesn't know what you want — the PRD is how you tell it.
A good spec follows a four-phase structure: Specify → Plan → Tasks → Implement. The PRD covers Specify and Plan. Ralph handles Tasks and Implement.
Running the Loop
Run ralph.sh from your project root. It scans .spec/ for spec files, lists them, and lets you pick one:
./ralph.sh
The script (ralph.sh) and instruction (ralph-instructions.md) is available here:
Each iteration, ralph does exactly one thing: it picks the highest priority user story where passes: false, implements it, runs your quality checks (lint, typecheck, tests), commits with feat: [Story ID] - [Story Title], then flips that story to passes: true in the PRD. When all stories pass, it outputs <promise>COMPLETE</promise> and exits.
Progress is written to .spec/<feature-name>.progress.txt after every iteration — what was implemented, files changed, and learnings for future iterations. Ralph also maintains a ## Codebase Patterns section at the top of that file, consolidating reusable discoveries (API conventions, gotchas, file dependencies) so later iterations don't repeat earlier mistakes.
A few honest caveats:
- Token limits are real. You will hit the rate limit on long runs. The good news: the loop is resumable. On restart, ralph reads the existing
.progress.txtand picks up from where it left off. - Security matters. My old laptop once restarted mid-run from the CPU load. Run long autonomous tasks in a confined environment — Docker is a good choice. Ralph runs claude with
--dangerously-skip-permissions, so containment matters. - Definition of done is non-negotiable. Ralph won't commit broken code — it runs quality checks before every commit. Make sure your acceptance criteria and test requirements are explicit in the PRD, or the AI will interpret "done" loosely.
Review and Merge
When the loop finishes, you have a PR. Now it's your job.
The AI generated code based on your PRD. If the output is wrong, that's feedback about your spec, not (only) about the AI. Review the PR critically:
- Does it match the acceptance criteria?
- Did it make unexpected architectural choices?
- Are the tests meaningful, or are they just passing?
Use semi-autonomous mode for corrections — describe what's wrong, let the AI fix it, review again. Update the PRD as you go. The PRD is a living document, and keeping it accurate means the AI has a trace record of every decision you made. Once satisfied, merge back to main. Trunk-based development keeps branches short-lived — one feature, one PR, merged fast.
Phase 3: Ship — Deploy
Once merged to main, deploy. Because we use trunk-based development, main is always the source of truth — every merge is a potential release. CI/CD picks it up from here. The setup of that pipeline is a separate topic I'll cover in a future post.
What I Left Out (Intentionally)
This is a minimal workflow. I deliberately excluded:
- Best practices and folder structure — this will be a future post
skills.mdconfiguration — worth exploring, but not required to start- CI/CD — essential for production, but out of scope for this post
The goal here is the smallest loop that produces consistent, reviewable code. Add complexity only when you feel the constraint.
The Full Picture
Phase 1 — Bootstrap: Get Your README Right
- Open Claude Code in Plan Mode and brainstorm high-level requirements
- Iterate until the plan feels right, then save to
README.md- Define: Problem, Architecture, Tech Stack
- README becomes the source of truth for all future PRDs
Phase 2 — Implement: PRD → Loop → Review → Merge
2a. Spec (.spec/<feature-name>.md)
For each feature, specify:
- User Stories — with acceptance criteria and
passes: falseon each - Non-Functional Requirements — latency targets, throughput, security, observability
- API Contract — REST resource hierarchy + HTTP conventions, or gRPC
.protodefinitions + streaming patterns - Data Model — entities, relationships, indexing strategy, schema migration approach, storage boundaries
- Cross-Cutting Scenarios — edge cases, permissions, error states
- Out of Scope — explicit exclusions
Review Spec with your team before handoff. The Spec is how you tell the AI what you want.
2b. Execute (./ralph.sh)
Pick story (passes: false)
→ Implement
→ Lint / Typecheck / Test
→ Commit: feat: [Story ID] - [Title]
→ passes: true
→ Repeat until all stories pass
→ Output: COMPLETE
- Progress logged to
.spec/<feature-name>.progress.txtafter every iteration - Loop is resumable — ralph reads progress on restart and picks up where it left off
- Run inside Docker for safety (
--dangerously-skip-permissionsis in play)
2c. Review and Merge
- Review PR against acceptance criteria
- Use semi-autonomous mode for corrections
- Update the Spec as you go — it's a living document
- Merge to
main(trunk-based, short-lived branches)
Phase 3 — Push: Ship It
- Every merge to
mainis a potential release - CI/CD pipeline picks it up automatically
mainis always the source of truth
Key Takeaways
- Chat alone gives inconsistent code. You need persistent, structured context.
- Init once, iterate many times. README is the foundation; PRDs drive each feature.
- The loop is resumable. Token limits are a fact of life, not a blocker.
- Deploy closes the loop. Review the PR, merge, ship — then start the next feature.
What's Next
Explore skills.md — it lets you teach Claude Code reusable workflows specific to your project. You can also look into how to write a good spec for deeper guidance on structuring your PRDs.
The barrier to building has dropped. The barrier to building well is now about how clearly you can think — and how precisely you can write it down.
Have a workflow that works better for you? I'd love to hear it.